Dip-NeRF: Depth-Based Anti-Aliased Neural Radiance Fields
Abstract
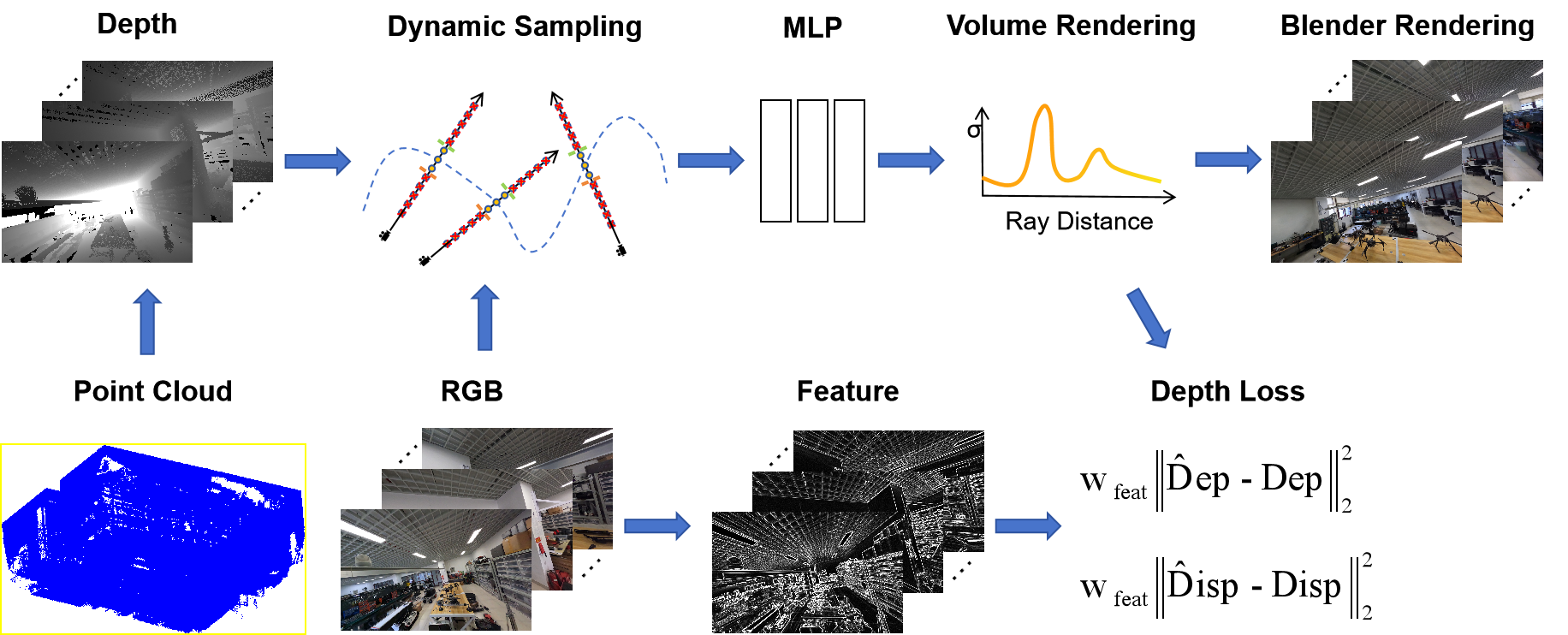
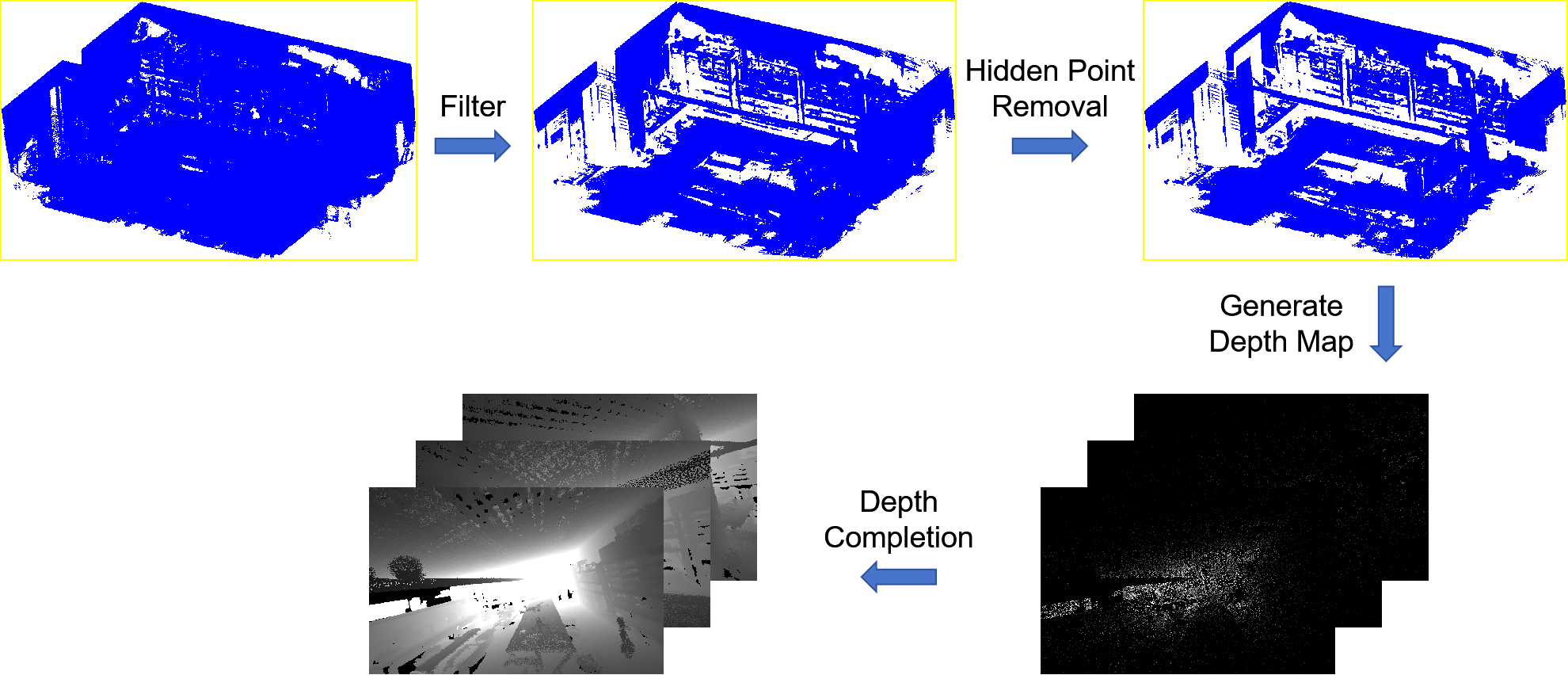
Neural radiation field (NeRF)-based novel view synthesis methods are gaining popularity for their ability to generate detailed and realistic images. However, most NeRF-based methods only use images to learn scene representations, ignoring the importance of depth information. The Zip-NeRF method has achieved impressive results in unbounded scenes by combining anti-aliasing techniques and mesh representations. However, the method requires a large number of input images and may perform poorly in complex scenes. Our method incorporates the advantages of Zip-NeRF and incorporates depth information to reduce the number of required images and solve the scale-free problem in borderless scenes. Experimental results show that our method effectively reduces the training time.And we can generate high-quality images and fine point cloud models using few images, even in complex scenes with numerous occlusions.

Comparison


Each scene comprises a panorama and a local view for comparison purposes. Our method demonstrates excellent results for both panoramic and local views. The original NeRF does not incorporate an additional prior to guide model training or prediction, resulting in the significant blurring of newly rendered views using sparse sample points. DoNeRF uses depth information to train the sampling Oracle network, which assists the model in identifying optimal sampling locations. However, when the number of input images decreases, the prediction accuracy of the sampling Oracle network also decreases, resulting in a blurred new view. Although Zip-NeRF shows good results, it lacks depth information constraints, leading to missing and blurred details. Our method introduces a depth prior in the sampling method and the loss function to effectively guide the model to render high-quality images despite the reduced input images. It should be noted that DoNeRF exhibits poor performance on real scene datasets due to its heavy reliance on accurate depth information, whereas our approach can produce good results without requiring high-quality depth information.
Ablation Studying

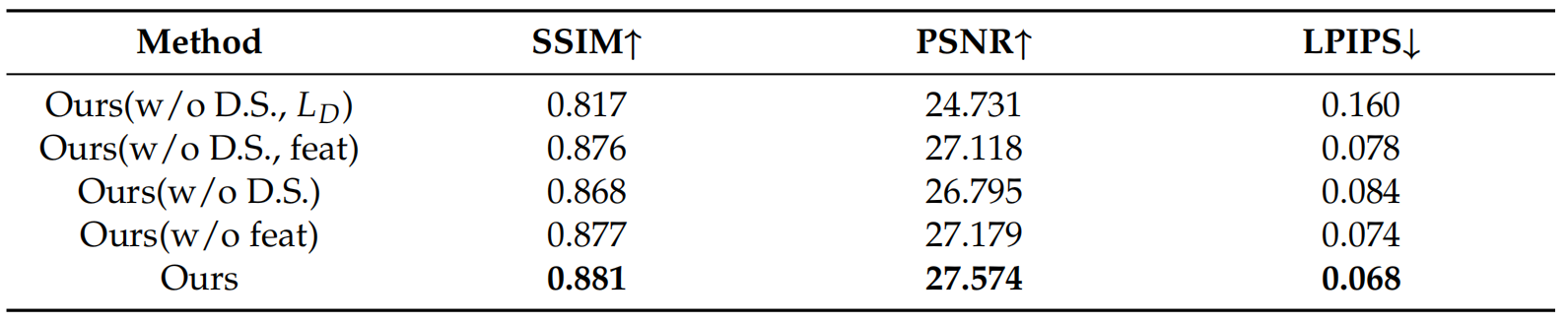
The ablation study clearly shows that the omission of dynamic sampling and depth loss leads to significant blurring and ghosting. Additionally, the lack of dynamic sampling methods results in a large number of invalid samples, which significantly impacts convergence speed and hinders the generation of high-quality rendered images within a short period. And, the absence of depth loss causes a focus solely on image information, disregarding depth information that could serve as a constraint. Furthermore, utilising a simple depth loss function without incorporating feature weights can result in indistinct occlusions near occluded objects and loss of detail due to the overbearing influence of depth information. As a result, it is imperative to differentiate the reliability of depth information in various regions by incorporating feature weights. Additionally, neglecting dynamic sampling methods increases the distance between sampling points and affects the convergence of the model. This can also make it difficult to accurately estimate the surface location of objects, resulting in blurred rendered images and the appearance of airborne floaters in the scene. If feature weights weighted according to depth loss are not used, some details may become blurred due to a possible lack of accurate depth information. Additionally, smoothed regions that should be more dependent on depth information may have uneven colours due to the excessive influence of the image.
BibTeX
@article{qin2024dipnerf,
title={Dip-NeRF: Depth-Based Anti-Aliased Neural Radiance Fields},
author={Qin, Shihao and Xiao, Jiangjian and Ge, Jianfei},
journal={Electronics},
year={2024},
publisher={MDPI}
}